

Early on at FireMon (well, before we became FireMon), we realized that attempting to live-assess customers’ cloud accounts (including subscriptions/projects) was… problematic. Running that many assessments would quickly hit service limits and could potentially disrupt a customer’s internal API calls. Keep in mind that we started doing this about 7 years ago, before CSPM even existed, and everyone was learning the same lessons.
The first solution we came up with was to collect configuration data once, input it into our own inventory, and then perform our assessments there. This allowed us to reduce our API calls to only what was necessary to retrieve the metadata. Then, we could run multiple assessments based on the same dataset. For a while, this approach worked well. We still performed time-based configuration scans, but we could spread them out more evenly and optimize to minimize the overload of API calls. However, this approach had its own set of issues. What if something changed between our scan and when someone finally went in to manage the alert? Additionally, sweeping through a full AWS service for all resources in that service would still strain against API limits, which are based on the service and region.
We set two challenges for ourselves to address this situation better. First, we aimed to update the inventory in real-time to reduce API call spikes to a given service and ensure that customers never worked with outdated data. Second, we aimed to maintain a history so that customers and investigators could look back and see exactly what changed and how it changed. We’ll delve into the technical architecture later, and it varies slightly for each cloud platform. In brief, by directly connecting to the cloud provider’s event stream, we could identify change API calls, extract the involved resources, update our inventory in real-time, and trigger all our assessments for a given inventory type simultaneously.
While we still support this with a once-a-day/off-hours time-based sweep, transitioning to real-time addressed many issues and produced some interesting benefits. These benefits include:
- Customers never encounter stale data; everything in the platform should closely match the actual running configuration/state.
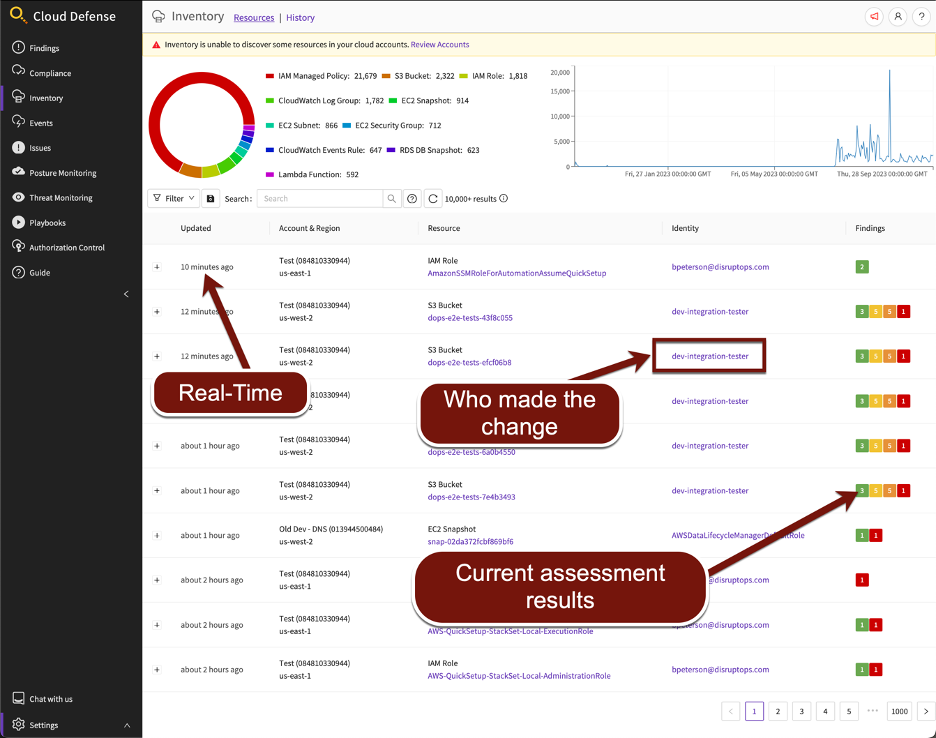
- As we monitor the API calls, we can identify who made those calls. Suddenly, we have complete identity attribution in our inventory.
- It becomes easy to pinpoint what changed as changes are made, providing comprehensive change tracking.
- We can run all checks and assessments in real-time as changes occur. This includes RESOLVING issues as someone rectifies them externally, not just identifying new issues.
Boom. A complete real-time, change-tracked, identity-attributed historical inventory! Yes, something like AWS Config provides this functionality natively within the cloud provider. However, aside from being cost-effective, our inventory and assessments are tightly integrated, cover multiple cloud deployments and providers, and offer some pretty impressive capabilities, such as comprehensive search functionalities.
The best way to experience this is through our 90-second video tour!
And here are a few key screenshots:
Main page, displaying a wealth of important data in a single view:
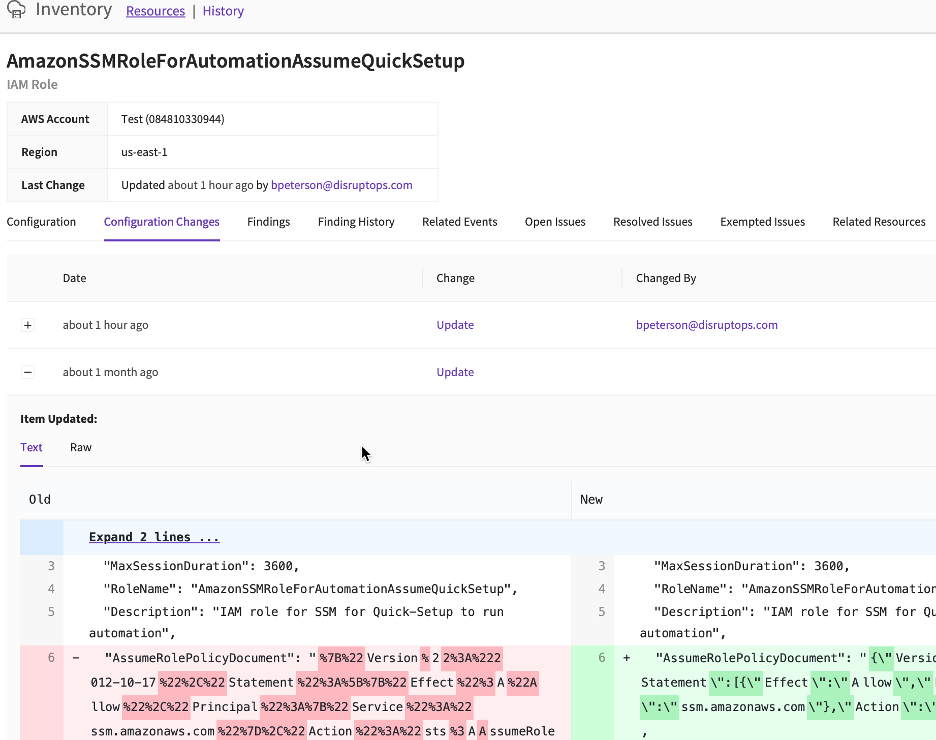
Here’s the change history view, presenting changes with full details and attribution. It also boasts useful features like related events, associated resources, exemptions, and a history of pass/fail findings for the resource:
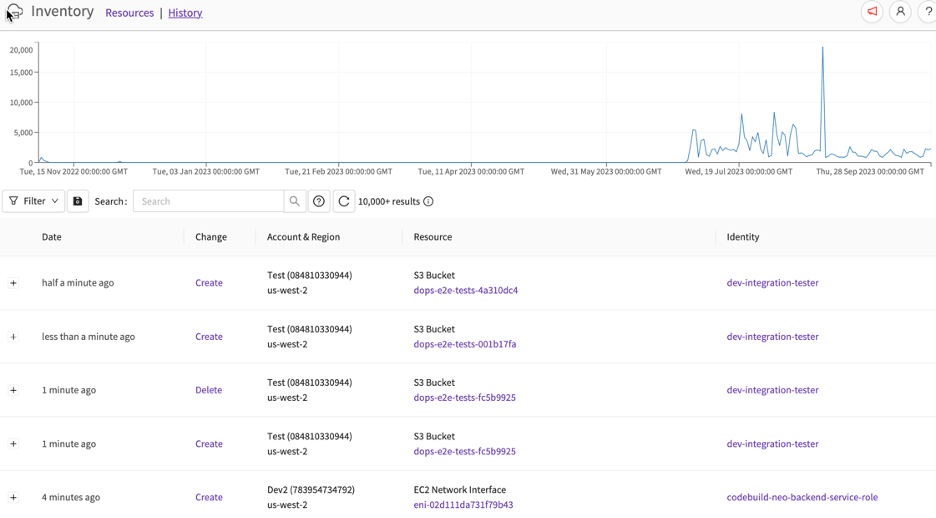
This History view tracks changes chronologically with a graph depicting activity trends. Clicking on the timeline jumps to that date:
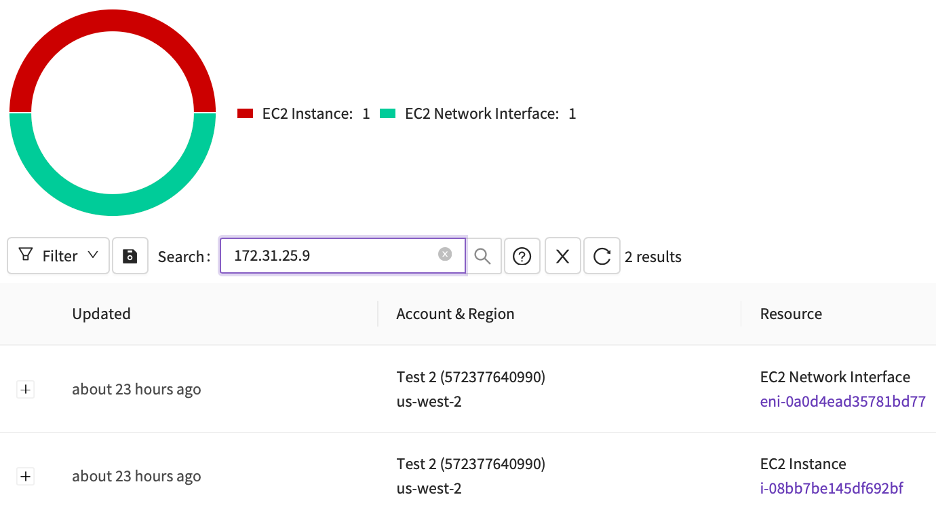
Have you ever needed to know which ephemeral cloud resource owned the IP address that appeared in the logs at a specific point in time? Incident responders love this one…
And that’s the quick overview. In future posts, we’ll provide more insight into the architecture and how we handle this for multi-cloud environments.